 Давненько я ничего не переводил. Решил вспомнить, каково это. Сегодня решил перевести статью из блога компании 2ndquadrant «PostgreSQL 12: Partitioning is now faster».
Давненько я ничего не переводил. Решил вспомнить, каково это. Сегодня решил перевести статью из блога компании 2ndquadrant «PostgreSQL 12: Partitioning is now faster».
Статья посвящена секционированию PostgreSQL 12 версии.
Секционирование таблиц в PostgreSQL появилось в 10-й версии и постоянно развивается. В 11-й версии появилось секционирование по хэшу, секции по умолчанию, автоматическое перемещение записи в нужную секцию после UPDATE’a, исключение ненужных секций во время SELECT’a и некоторые другие возможности.
В PostgreSQL 12 большое внимание уделено масштабированию секционирования, чтобы оно работало с большим числом разделов (тысячами). Посмотрим, что было улучшено.
Производительность копирования (COPY)
Загрузка данных в секционированную таблицу с использование COPY теперь позволяет использовать массовые вставки (bulk-inserts). Ранее, за один раз добавлялась только одна строка.
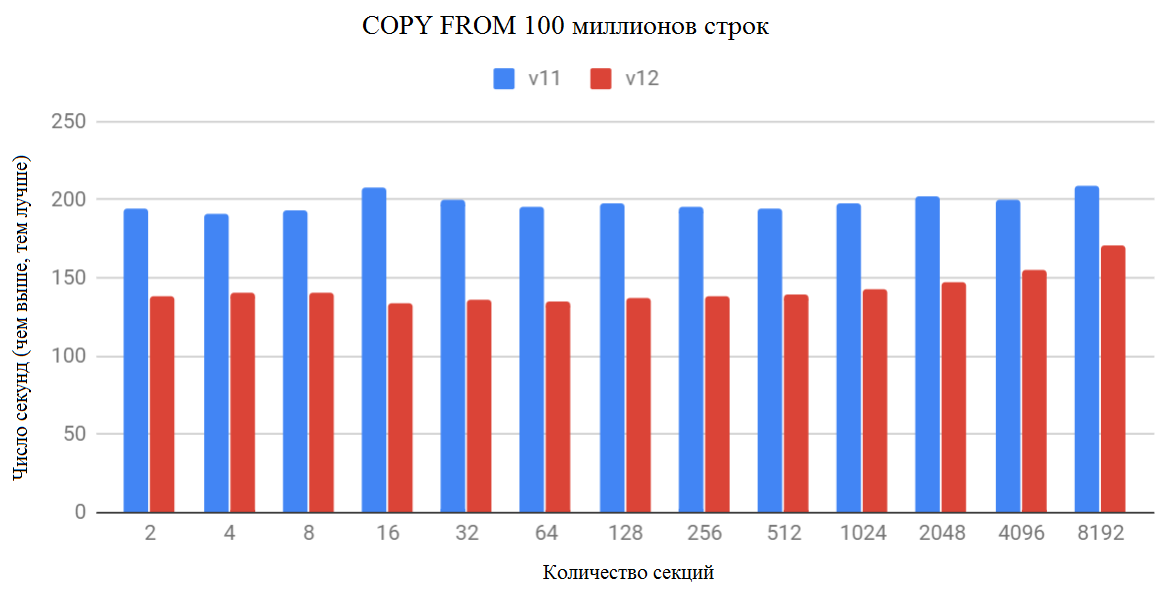
Скорость COPY, по-видимому, замедляется при увеличении количества секций, но, в действительности, она уменьшается с меньшим количеством строк на раздел. В этом тесте с увеличением количества разделов, количество строк на раздел сокращается. Причина замедления заключается в том, что код COPY составляет до 1000 слотов для каждой строки на секцию. В действительности такого снижения производительности, скорее всего, не произойдет, поскольку у вас может быть более 12,2 тыс. строк на секцию.
Производительность вставки (INSERT)
В PostgreSQL 11, при вставке записей в секционированную таблицу, каждый раздел блокировался, независимо от того, добавлялась ли запись в него или нет. При большем количестве разделов и меньшем количестве строк в INSERT, эти издержки могут стать значительными.
В PostgreSQL 12 секция блокируется непосредственно перед первой вставкой строки. Это означает, что если вставляем только 1 строку, то блокируется только 1 секция. Это приводит к гораздо лучшей производительности при большем количестве секций, особенно при вставке только 1 строки за раз. Это изменение в поведении блокировки также было объединено с полной перепиской кода маршрутизации строки секции. Благодаря этому, значительно снижаются накладные расходы на настройку структур данных маршрутизации кортежей во время запуска исполнителя планов (executer’a).
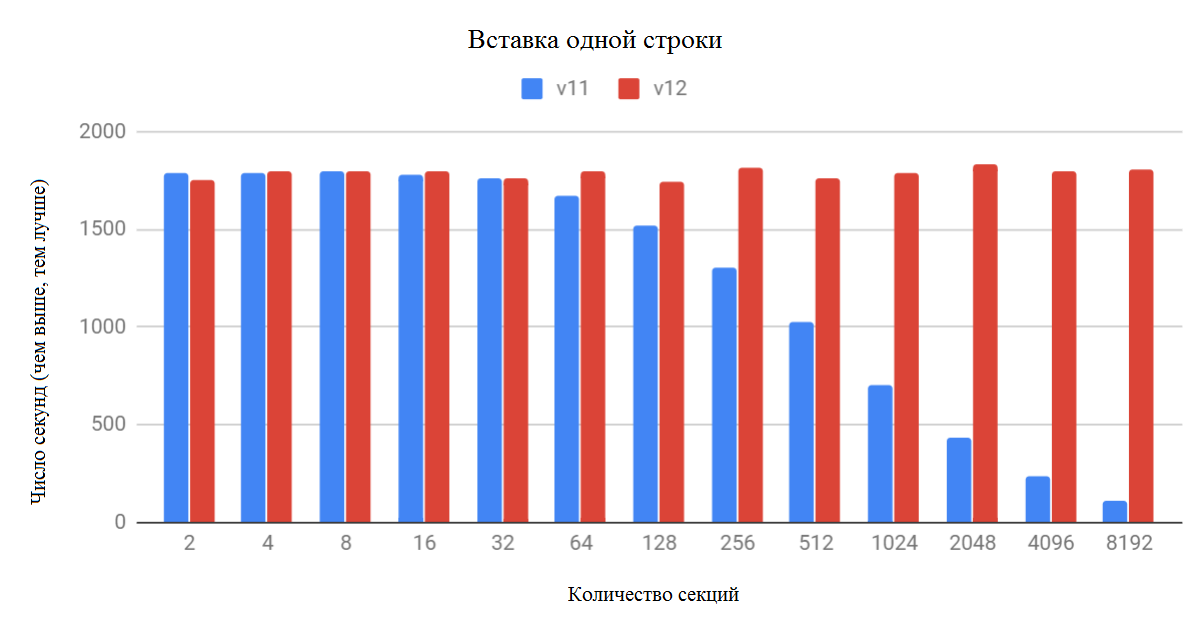
Можно видеть, что производительность в PostgreSQL 12 достаточно стабильна независимо от того, на сколько секций разделена таблица.
Производительность выборки (SELECT)
В PostgreSQL 10 планировщик последовательно проверяет ограничения каждой секции чтобы выяснить, нужно ли брать информации из нее для запроса. Это приводило к увеличению накладных расходов на планирование при увеличении количества секций. В PostgreSQL 11 улучшили эту работу за счет исключения ненужных секций (partition pruning), с помощью которого можно намного быстрее найти подходящие секции. Тем не менее, PostgreSQL 11 все еще выполнял некоторую ненужную обработку и по-прежнему загружал метаданные для каждой секции, независимо от того, была ли она исключена или нет.
В PostgreSQL 12 исправили данное поведение – загрузка метаданных выполняется после исключения секций. Это приводит к значительному повышению производительности в планировщике запросов при исключении многих секций.
Приведенная ниже диаграмма показывает производительность запроса отдельной строки из хэш-секционной таблицы, разбитой по столбцу BIGINT, который также является первичным ключом таблицы. В данном случае, могут быть удалены все секции, кроме единственной (необходимой).
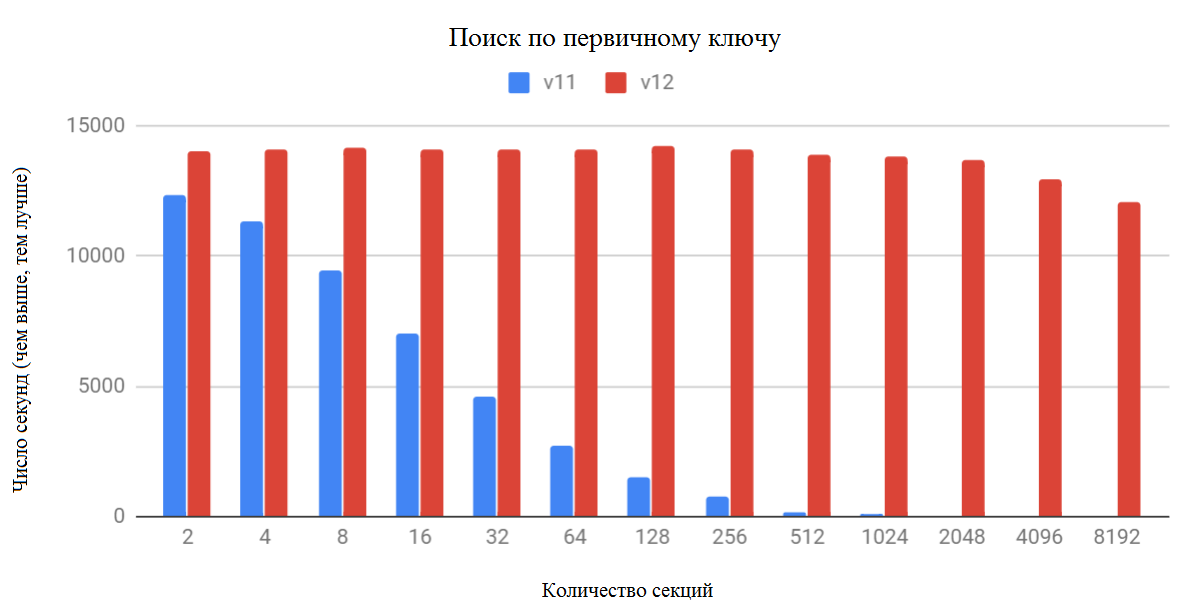
По диаграмме отлично видно, что PostgreSQL 12 значительно улучшает ситуацию. При увеличении количества разделов, производительность немного падает. Но она все еще на несколько световых лет опережает PostgreSQL 11 в этом тесте 🙂
Другие улучшения производительности секционирования
Упорядоченное сканирование разделов:
Планировщик теперь может использовать неявный порядок секционированных таблиц по методу списка (LIST) и диапазона (RANGE). Это позволяет использовать оператор Append вместо оператора MergeAppend, когда требуемым порядком сортировки является порядок, определенный ключом секции. Это невозможно для хэш-секционированных таблиц, так как различные неупорядоченные значения могут совместно использовать один и тот же раздел. Эта оптимизация уменьшает бесполезные сравнения сортировки и обеспечивает хороший задел для запросов, использующих предложение LIMIT.
Избавьтесь от отдельных вложенных планов Append и MergeAppend:
Это довольно тривиальное изменение, которое устраняет узлы Append и MergeAppend, когда планировщик видит, что у него есть только один подузел. В этом случае было совершенно бесполезно сохранять узел Append/MergeAppend, поскольку они предназначены для добавления нескольких результатов подплана вместе. Делать особо нечего, когда уже есть только 1 подплан. Удаление их также дает небольшой прирост производительности для запросов, поскольку извлечение строк через ноды executor’a, независимо от того, насколько они тривиальны, не является бесплатным. Это изменение также позволяет распараллеливать некоторые запросы к секционированным таблицам, которые ранее не могли быть распараллелены.
Различные улучшения производительности для исключения секций во время выполнения:
Значительная часть оптимизационной работы была также проделана вокруг исключения разделов во время выполнения (run-time), чтобы уменьшить накладные расходы при запуске exectutor’a. Кроме того, была проделана определенная работа, позволившая PostgreSQL использовать расширенные инструкции по манипулированию битами, что повысило производительность типа Bitmapset. Это позволяет поддерживать процессоры для выполнения различных 64-х битных операций одновременно в единственной операции. Ранее все эти операции проходили через Bitmapset по 1 байту за раз. Эти Bitmapsets также были изменены с 32-битных на 64-битные на 64-разрядных машинах. Это эффективно удваивает производительность работы с большими Bitmapsets.
Некоторые изменения были также внесены в executor, чтобы таблицы диапазонов (для хранения метаданных отношений) можно было найти в O(1), а не O(N) времени, где N-количество таблиц в списке таблиц диапазонов. Это особенно полезно, поскольку каждый раздел в плане имеет запись таблицы диапазонов, поэтому поиск данных таблицы диапазонов для каждого раздела был дорогостоящим, когда план содержал много разделов.
Благодаря этим улучшениям и использованию метода RANGE, с секционированием по столбцу timestamp, где каждая секция хранит 1 месяц данных, производительность выглядит следующим образом:
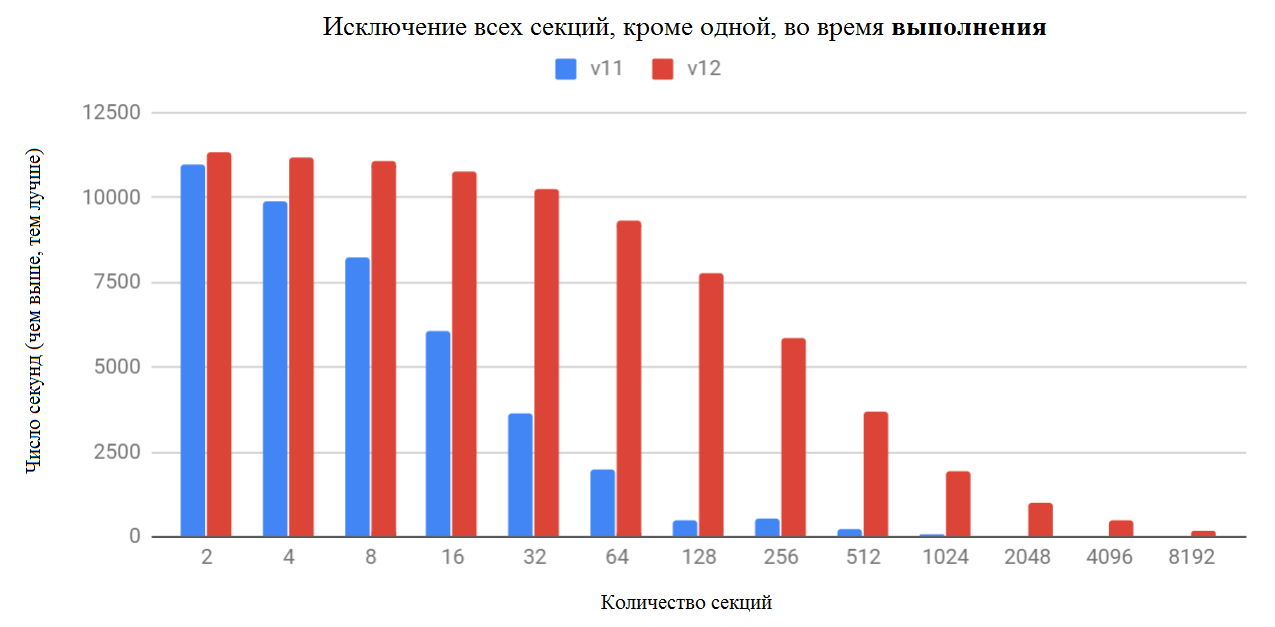
Здесь можно увидеть, что выигрыш PostgreSQL 12 становится больше с большим количеством разделов. Однако, высота столбцов уменьшается при увеличении количества секций. Это происходит потому, что сформирован запрос таким образом, что в плане исключение секций невозможно. Выражение WHERE имеет STABLE-функцию (стабильную функцию, гарантированно возвращающую одинаковый результат), планировщик не знает её возвращаемого значения, поэтому не может исключить какие-либо секции. Возвращаемое значение вычисляется во время запуска executor’a, а исключение раздела выполняется во время выполнения. К сожалению, это означает, что executor должен заблокировать все разделы плана, даже те, которые будут исключены во время выполнения. Так как этот запрос выполняется быстро, накладные расходы на эту блокировку можно увидеть только при большом количестве секций. Но исправлять это будут только в следующей версии.
Хорошая новость заключается в том, что если мы изменим предложение WHERE, заменив вызов STABLE-функции на константу, планировщик сможет позаботиться об исключении секций:

Накладные расходы на планирование показывают, что здесь, как и в случае с несколькими секциями, производительность PostgreSQL 12 не так высока, как в случае с общим планом и исключением секций во время выполнения. При большем количестве секций производительность не так сильно снижается, когда планировщик может выполнить исключение. Это происходит потому, что план запроса имеет только 1 секцию для блокировки и разблокировки executor’ом.
Резюме
Из приведенных выше графиков видно, что было много сделано для улучшения секционирования в PostgreSQL 12. Однако, пожалуйста, не поддавайтесь соблазну приведенных выше графиков и разработайте свои стратегии секционирования с большим количеством секций. Имейте в виду, что всё еще есть случаи, когда слишком много секций может привести к тому, что планировщик запросов будет использовать больше оперативной памяти и станет медленным. Когда производительность имеет значение (а это обычно всегда так) мы настоятельно рекомендуем Вам запустить моделирование рабочей нагрузки. Это следует делать не на рабочем сервере, с различным количеством разделов, чтобы увидеть, как это влияет на производительность. Прочтите раздел документации, посвященный лучшим практикам, для получения дальнейших указаний.
Тестовая среда:
Все тесты были выполнены на экземпляре Amazon AWS m5d.large с использованием pgbench. Количество операций в секундах (transactions per seconds) тестов измерялось в течение 60 секунд.
Были изменены следующие настройки:
shared_buffers = 1GB work_mem = 256MB checkpoint_timeout = 60min max_wal_size = 10GB max_locks_per_transaction = 256
Всё количество транзакций в секунду измерялось с помощью одного соединения PostgreSQL.
И еще раз — ссылка на оригинал: «PostgreSQL 12: Partitioning is now faster».
Leave a Reply