Я провел множество экспериментов с shared_buffers, и мои эксперименты продолжаются. В этот раз решил описать эксперимент, в котором я смотрю что будет, если уменьшить размер кэша PostgreSQL. К чему это приведет и как это посмотреть – ниже.
Когда не хватает выделенной shared_buffers:
Пытался придумать хороший пример на моей не нагруженной системе. В итоге, у меня получился громоздкий пример. Но, пока я придумывал, как его реализовать, кучу всего нового узнал:
Подготовка:
Нужно установить расширение pg_prewarm, которое используется для прогрева кэша PostgreSQL. В состав данного расширения входит функция pg_prewarm, в параметр которой нужно передать объект, который будет принудительно загружен в кэш (либо PostgreSQL, либо ОС):
- CREATE EXTENSION pg_prewarm;
Создаем таблицу t с одним полем id типа numeric:
- CREATE TABLE t(id numeric);
Меняем способ хранения «длинных» значений в колонке данной таблицы на plain – не будет использоваться никакой способ сжатия и не будут использоваться TOAST-таблицы:
- ALTER TABLE t ALTER COLUMN id SET STORAGE PLAIN;
Включаем замер операций вводы/вывода (параметр track_io_timing) и перечитаем конфигурацию, чтобы замер времени заработал:
- ALTER SYSTEM SET track_io_timing = on;
- SELECT pg_reload_conf();
Далее забиваем таблицу большими данными:
- INSERT INTO t SELECT 120^12345::numeric from generate_series(1,65000);
В данном инсерте я вставляю 65 000 строк в таблицу t с единственным значением, которое очень большое (120 в степени 12345).
Проверяем размер таблицы (я использую psql):
- \dt+ t
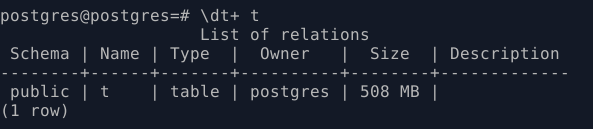
Размер моей таблицы 508 МБ. Под этот размер установлю значение shared_buffers в значение 512 МБ. При установке нового значения shared_buffers не забудьте перезапустить сервер PostgreSQL. В момент перезагрузки очистится совместная память PostgreSQL, что нам и нужно.
Для супер-чистоты эксперимента я перезапустил виртуалку, запустил PostgreSQL.
Эксперимент:
- Считываем таблицу с диска
Выполним запрос:
- EXPLAIN (ANALYZE, BUFFERS) select * from t;
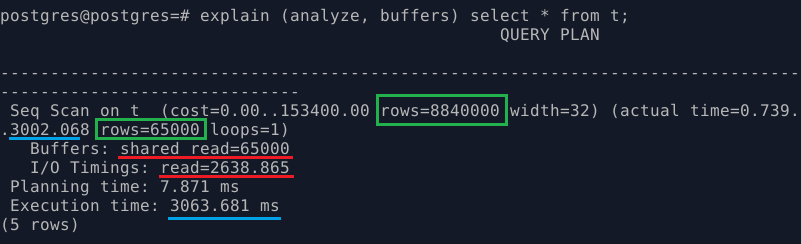
Данным запросом просим PostgreSQL выполнить запрос и показать фактическое время его выполнения, чтения буферов, количество строк:
В выводе EXPLAIN видно план и факт выполнения.
Seq Scan – сокращение от sequential, означает последовательное чтение всей таблицы. У меня нет индексов, да и значения вроде как все нужны, поэтому тут всё нормально.
По какой-то причине, планировщик посчитал, что у меня в таблице будет почти 9 миллионов строк (я эксперименты проводил, таблицу чистил, а статистику не обновлял). Фактически было выбрано 65 тысяч строк.
В секции buffers можно увидеть строку shared read 65000. Подобрал такой размер таблицы, чтобы одна строка была примерно равна 8 КБ, то есть, одной странице в общей памяти. shared read показывает, сколько чтений было осуществлено НЕ ИЗ shared_buffers PostgreSQL – с диска, или из буфера ОС. В данном случае PostgreSQL прочитал 65000 строк-страниц с диска.
I/O Timings – на чтение этих 65000 страниц PostgreSQL потратил примерно 2.5 секунды. Если в секцию actual time посмотреть, последний параметр (после двоеточия, на второй строке) стоит 3000 миллисекунд – 3 секунды. За три секунды сервер получил все 65000 строк, из этих 3 секунд он 2.5 секунды только читал данных с диска.
Всего на отработку запроса ушло чуть более 3 секунды (3063 миллисекунды) – последняя строка.
Если несколько раз повторно выполнить данный запрос, скорость получения данных будет немного увеличиваться:
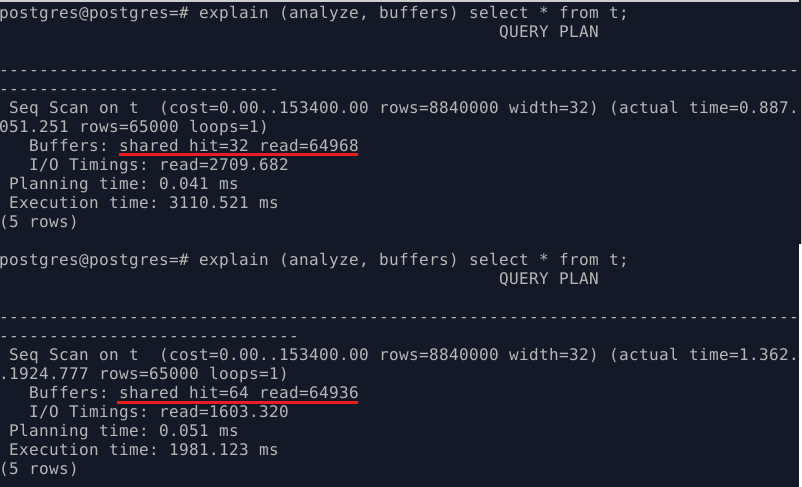
Появился элемент shared hit – это чтения из shared_buffers. У меня по 32 страницы туда попадает, пока с этим не разбирался. Второй раз выборка данных НЕ ИЗ shared_buffers происходит значительно быстрее, чем в первые разы. Я считаю, это связано с тем, что данные попали в буферный кэш операционной системы. Shared read, напоминаю, показывает чтения только из shared_buffers.
- Считываем таблицу из shared_buffers
Выполним запрос:
- SELECT pg_prewarm(‘t’);
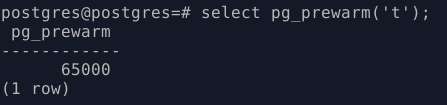
С помощью расширения pg_prewarm загоняем всю таблицу t в shared_buffers. В общий буфер PostgreSQL было занесено 65000 страниц, как раз все строки нашей таблицы t.
Снова выполняем предыдущий запрос на анализ чтения данных из таблицы:
- EXPLAIN (ANALYZE, BUFFERS) select * from t;
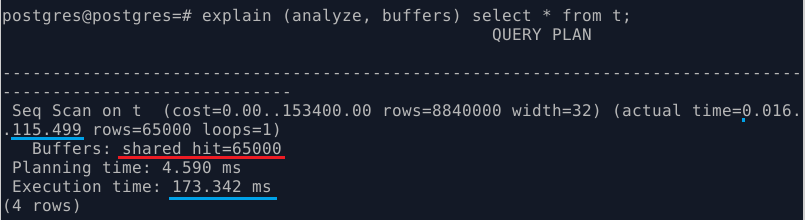
В данном случае время на чтение данных не тратится (нет раздела I/O Timings), есть только shared hit = 65000. Это означает, что, при исполнении данного запросы все строки были получены из shared_buffers и очень-очень быстро.
Если повторно выполнить запрос – результат будет примерно тем же самым:
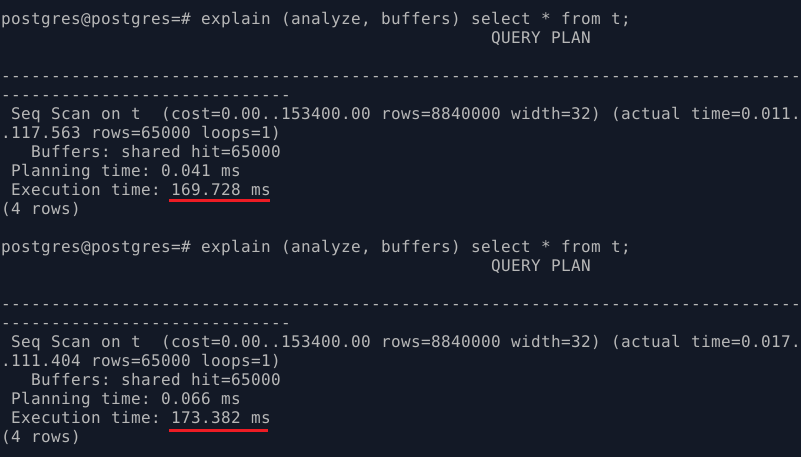
Итоговое время выполнения запроса более чем на порядок меньше, чем первоначальное.
В данном случае у нас shared_buffers был равен 512 МБ, и в него полностью помещалась наша тестовая таблица.
- Уменьшаем shared_buffers до 128кБ
В postgresql.conf меняем значение параметра до 128 кБ, перезапускаем сервер PostgreSQL, чтобы освободить буфер сервера, перезапускаем ОС для очистки совести.
Снова выполняем запрос:
- EXPLAIN (ANALYZE, BUFFERS) select * from t;
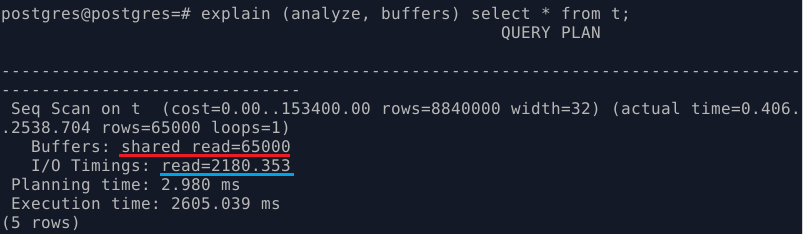
Результат, собственно, такой же, как и был в первый раз. Всё читаем с диска, тратим время на это, почти три секунды.
Сейчас не особенно показательно, так как всё ожидаемо. Далее снова загрузим таблицу в shared_buffers PostgreSQL:
- SELECT pg_prewarm(‘t’);
Нам сообщается, что загружено 65000 страниц. Я думаю, просто по очереди блоки закидывались в общую память PostgreSQL, предыдущие выкидывались оттуда.
А теперь снова запустим запрос:
- EXPLAIN (ANALYZE, BUFFERS) select * from t;

Хоть нам мы и ожидаем, что таблица будет в кэше PostgreSQL, но по факту (при наличии крошечного shared_buffers) у нас в него попадает только 14 страниц: 14*8=112 КБ данных. А все остальные страницы читаются с диска, на это тратится время.
Выполним запрос еще несколько раз:
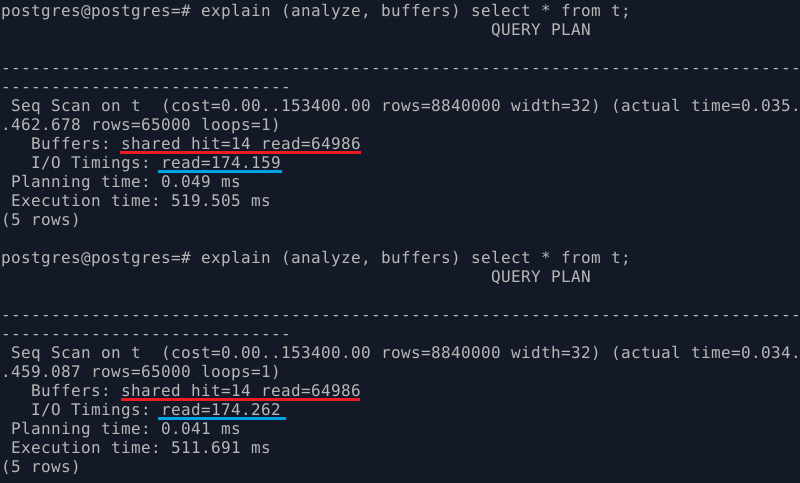
Скорость получения данных не из shared_buffers увеличилась. Но, повторюсь, я считаю, что это произошло из-за того, что у меня не нагруженная система и таблица загрузилась в буферный кэш операционной системы.
Но можно увидеть, что shared hit как был 14, так и остался. Больше страниц в shared_buffers PostgreSQL загрузить не удается, так как у нас этот параметр установлен в небольшое значение.
Вот таким «нехитрым» и «небольшим» экспериментом можно увидеть, как влияет правильно подобранный параметр shared_buffers на производительность запросов.
У меня на этом не всё про буферный PostgreSQL.
Leave a Reply