 Продолжаю эксперименты с PostgreSQL. Ранее, я уже небольшие эксперименты проводил с max_connections и чуть побольше с shared_buffers (один и два). Конфигурационных параметров у PostgreSQL очень много, так что есть еще с чем поэкспериментировать. И каждый раз что-нибудь новое и непонятное нахожу.
Продолжаю эксперименты с PostgreSQL. Ранее, я уже небольшие эксперименты проводил с max_connections и чуть побольше с shared_buffers (один и два). Конфигурационных параметров у PostgreSQL очень много, так что есть еще с чем поэкспериментировать. И каждый раз что-нибудь новое и непонятное нахожу.
Про параметр work_mem можно почитать по ссылке.
- Создаю таблицу t1:
CREATE TABLE t1(id numeric);
- Заполняю её данными:
INSERT INTO t1 SELECT random()*10 from generate_series(1,210000);
- У меня уже установлено расширение pg_prewarm, но его можно поставить так:
CREATE EXTENSION pg_prewarm;
- Проверим размер таблицы t1:
\dt+ t1
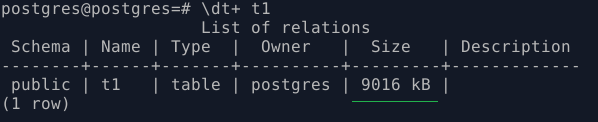
Размер для моих экспериментов подходящий.
Эксперимент:
- Ставим минимальный размер параметра work_mem:
Перехожу в конфигурационный файл postgresql.conf, нахожу этот параметр, меняю на значение 64kB (это минимум), перезагружаю PostgreSQL. Есть и другой способ, можно прямо в сеансе поменять данное (любое подходящее) значение параметров:
SET work_mem TO ’64kB’;
Кому как удобно.
С помощью pg_prewarm закидываю всю таблицу в shared_buffers:
SELECT pg_prewarm(‘t1’);
Это делать не обязательно 🙂
work_mem используется в сортировках и в операциях хэширования. Самый простой способ проверить его влияние – сделать сортировку. Выполняю запрос:
EXPLAIN (ANALYZE, BUFFERS) select * from t1 ORDER BY 1 DESC;
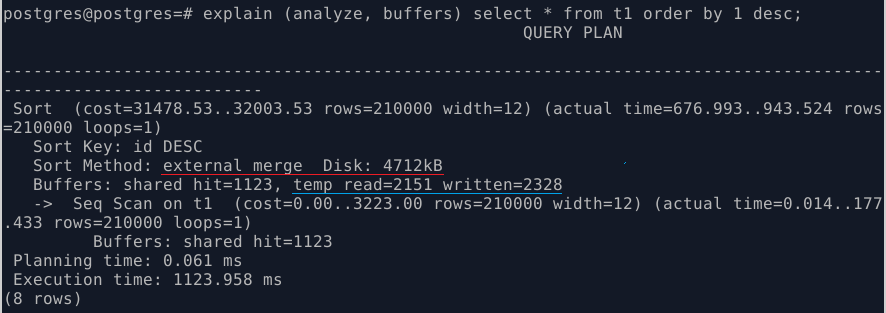
В эксплейне можно увидеть вот такую строку: Sort Method: external merge (внешнее слияние). Далее – показывается, где будет происходит эта «внешняя» операция – на диске. А проще говоря, используются временные файлы на диске.
Вот тут я еще не всё понял. Вроде как должны использоваться временные файлы размером 4712kB, всего 4 МБ при размере таблицы в девять МБ. А остальное где?
По факту (строка в эксплейне ниже) пишется 2328 блоков по 8 КБ – written=2328, а читается поменьше – 2151 блоков по 8 КБ. Но, всё-равно, это же 16 МБ и более! Вот этот момент я выяснял, не выяснил пока до конца.
Но факт, связанный с work_mem, вот в чем – при его нехватке (а 16 КБ не хватает для сортировки таблицы размером в 9 МБ, так как при сортировке нужно всю таблицу прочитать), PostgreSQL обращается ко временным файлам. Из эксплейна это можно увидеть. Если включить логирование обращений к временным файлам – можно увидеть, какие были созданы.
Shared hit=1123 – уже рассматривал данную строку в прошлых экспериментах. Это означает, что вся таблица находится в shared_buffers, поэтому её не нужно читать с диска (благодаря pg_prewarm).
- Ставим достаточный размер параметра work_mem:
Ставлю размер work_mem больший, чем размер таблицы, чтобы точно на всё хватило:
SET work_mem TO ’64MB’;
И выполняю тот же самый запрос:
EXPLAIN (ANALYZE, BUFFERS) select * from t1 ORDER BY 1 DESC;
Теперь результат будет отличаться:

Здесь уже метод сортировки quicksort (по-видимому, быстрая сортировка). Занимает памяти 12300 КБ – 12 МБ, всё равно больше, чем размер таблицы. Наверное, для сортировки нужен размер таблицы + еще какая-то память, не читал подробнее об этом.
Во всяком случае, скорость исполнения запроса уменьшилась – execution time стал меньше на время записи-чтения временных файлов.
Чтобы понять, почему только часть временных файлов создается, почему на сортировку нужно больше памяти, чем размер таблицы – во всём этом нужно еще разбираться.
Разбираюсь.
Leave a Reply